Plenoxels
Radiance Fields without Neural Networks
CVPR 2022 (Oral)
- UC Berkeley
- * Equal contribution
We propose a view-dependent sparse voxel model, Plenoxel (plenoptic volume element), that can optimize to the same fidelity as Neural Radiance Fields (NeRFs) without any neural networks. Our typical optimization time is 11 minutes on a single GPU, a speedup of two orders of magnitude compared to NeRF.
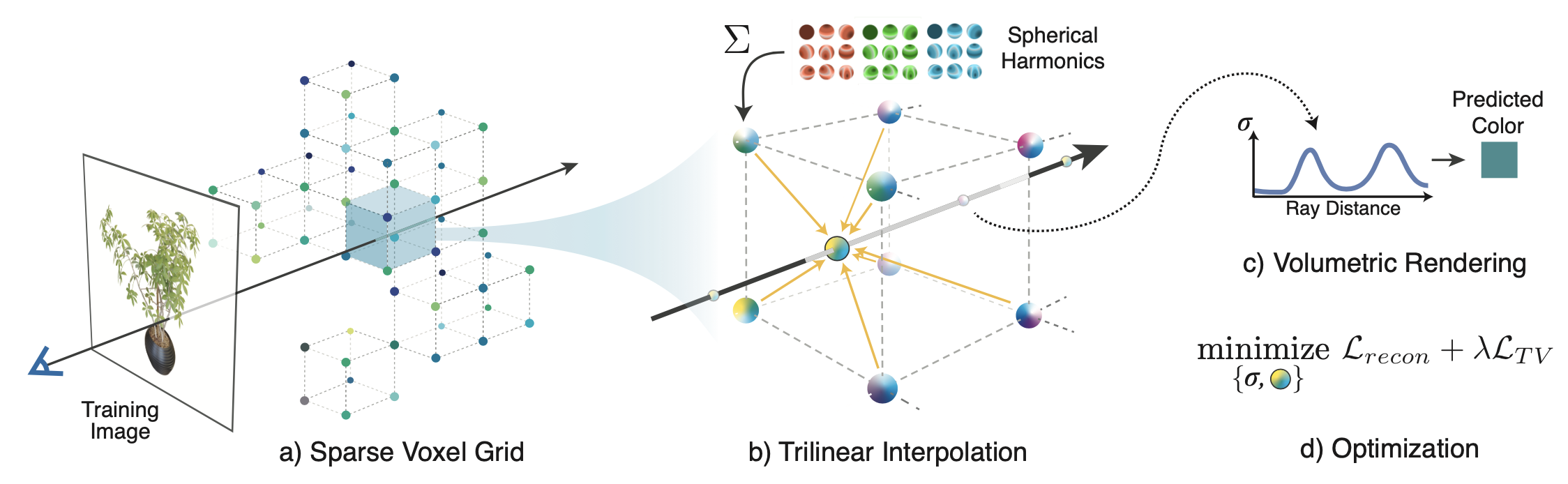
Given a set of calibrated images of an object or scene, we reconstruct a (a) sparse voxel (“Plenoxel”) grid with density and spherical harmonic coefficients at each voxel. To render a ray, we (b) compute the color and opacity of each sample point via trilinear interpolation of the neighboring voxel coefficients. We integrate the color and opacity of these samples using (c) differentiable volume rendering, following the recent success of NeRF. The voxel coefficients can then be (d) optimized using the standard MSE reconstruction loss relative to the training images, along with a total variation regularizer.
BibTeX
Note: joint first-authorship is not really supported in BibTex; you may need to modify the above if not using CVPR's format. For the SIGGRAPH format you can try the following
Superfast Convergence
Our method converges rapidly. We reach comparable metrics (PSNR) 100x faster than NeRF, and achieve reasonable results within a few seconds of optimization.
Results on Forward-facing Scenes
Using NeRF's NDC parameterization, we are able to approximately match NeRF's results on forward-facing scenes as well.
Results on 360° Scenes
We extend the method to 360° real scenes using a background model based on multi-sphere images (MSI), similar to the approach used in NeRF++.
Background / Foreground
The following is a capture of a real Lego bulldozer. We show the background and foreground models separately.
Full
Foreground
Background
Concurrent Works
Please also check out DirectVoxGo, a similar work which recently appeared on arXiv. They use a neural net to fit the color, but do not make use of TV regularization, SH, or sparse voxels. Additionally, their implementation does not require custom CUDA kernels.
Acknowledgements
We note that Utkarsh Singhal and Sara Fridovich-Keil tried a related idea with point clouds some time prior to this project. Additionally, we would like to thank Ren Ng for helpful suggestions and Hang Gao for reviewing a draft of the paper. The NeRF++ results were generously provided by the authors.
The project is generously supported in part by the CONIX Research Center, one of six centers in JUMP, a Semiconductor Research Corporation (SRC) program sponsored by DARPA; a Google research award to Angjoo Kanazawa; Benjamin Recht’s ONR awards N00014-20-1-2497 and N00014-18-1-2833, NSF CPS award 1931853, and the DARPA Assured Autonomy program (FA8750-18-C-0101). Sara Fridovich-Keil and Matthew Tancik are supported by the NSF GRFP.
This website is in part based on a template of Michaël Gharbi, also used in PixelNeRF and PlenOctrees.